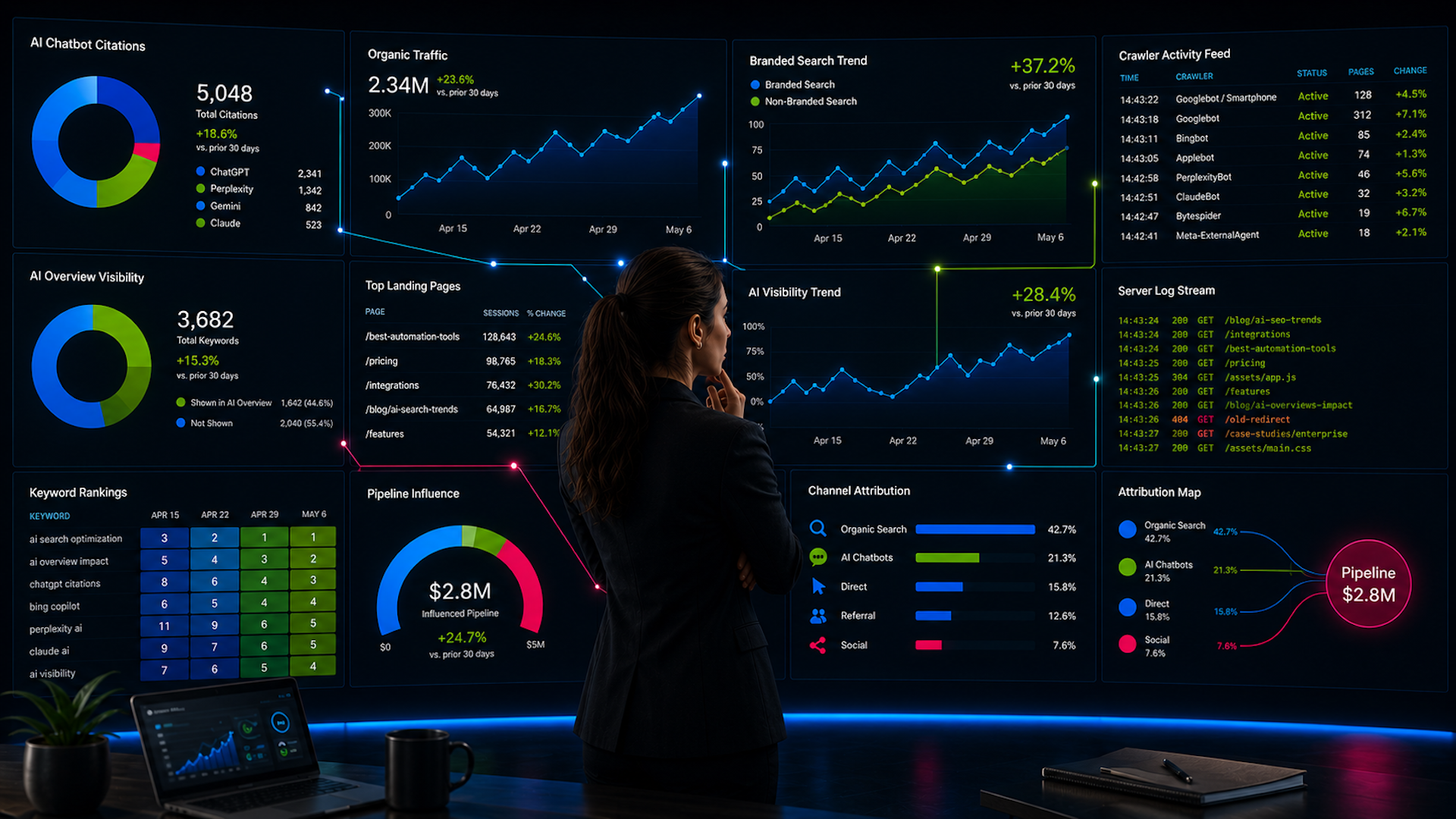

Giriş: Sitenize Gelen Ziyaretçiyi Hiç Görmüyorsunuz
Bir geliştirici Claude Code’u açıyor, bir görevi yazıp Enter’a basıyor. Yapay zeka ajanı dökümanlarınıza gidiyor — bir GET isteği gönderiyor, HTML’i soyup düz metni çıkarıyor, token’ları sayıyor ve sessizce içeriği ya kullanıyor ya da bağlam penceresi aşıldığı için siliyor.
Analitik panelinizdeyse hiçbir şey görünmüyor. Sayfa görüntülemesi: 400 milisaniye. Scroll derinliği: sıfır. Tıklama: yok.
Ama ajan oradaydı. Dökümanınızı okudu. Ve dökümanınızın yapısına bağlı olarak görevi başarıyla tamamladı — ya da yanlış yapılandırılmış bir robots.txt ya da aşırı token yükü yüzünden varsayımlara dayalı bir çözüm üretip hallüsinasyon yaptı.
İşte bu noktada Agentic Engine Optimization (AEO) devreye giriyor.
AEO Nedir?
Agentic Engine Optimization (AEO), teknik içeriklerin yalnızca insan okuyucular için değil, yapay zeka kodlama ajanlarının aktif olarak okuyup kullanabileceği şekilde yapılandırılması, biçimlendirilmesi ve sunulması pratiğidir.
Analoji oldukça güçlü: SEO’yu düşünün. Yıllarca arama motorı tarayıcıları ve insan tıklama davranışları için optimize etmeyi öğrendik. AEO de aynı mantık — ama bu sefer müşteri farklı: içerikleri otonom olarak çekip analiz eden ve üzerinde akıl yürüten yapay zeka ajanları.
AEO’da Önem Taşıyan Beş Temel Boyut
- Keşfedilebilirlik: Ajanlar, JavaScript render etmeden dökümanlarınızı bulabiliyor mu?
- Ayrıştırılabilirlik: İçerik, görsel düzen yorumlaması gerektirmeden makine tarafından okunabilir mi?
- Token Verimliliği: İçerik, kesilme olmaksızın tipik ajan bağlam pencerelerine sığıyor mu?
- Kapasite Sinyali: Döküman, API’nizin nasıl çağrılacağını değil, ne yaptığını anlatıyor mu?
- Erişim Kontrolü:
robots.txtyapay zeka trafiğine gerçekten izin veriyor mu?
Bu boyutlardan herhangi biri başarısız olursa ajanlar ya içeriği tamamen atlıyor ya da yanlış çıktılar üretiyor. Üstelik hiçbir analitik eventi tetiklenmediği için bundan haberin de olmayacak.

Yapay Zeka Ajanları Dökümanlarınızı Nasıl Okuyor?
İnsan ile ajan davranışı arasındaki fark, ilk bakışta göründüğünden çok daha büyük.
İnsan Davranışı
Bir geliştirici döküman ana sayfanıza geliyor. İlgili bölüme geçiyor, başlıkları tarıyor, birkaç paragraf okuyor, interaktif konsolda kod örneği çalıştırıyor, iki-üç iç bağlantıyı takip ediyor ve oturumda 4-8 dakika geçiriyor. Analitik tüm bunları kaydediyor.
Ajan Davranışı
Claude Code, Cursor, Cline, Aider, VS Code ve Junie gibi dokuz büyük yapay zeka kodlama ajanının HTTP trafiğini inceleyen bir araştırmaya göre ajanlar, çok sayfalı gezinmeyi genellikle bir ya da iki HTTP isteğine sıkıştırıyor. Bir insanın döküman hiyerarşinizde dakikalarca tıklayarak geçireceği yeri, bir ajan tek bir GET isteği göndererek sayfanın tamamını alıp geçiyor.
“Kullanıcı yolculuğu” kavramı tek bir sunucu taraflı olaya dönüşüyor.
Pratik sonuç: Her istemci taraflı analitik eventi — scroll derinliği, sayfada geçirilen süre, buton tıklamaları, eğitim tamamlamaları, bağlantı takipleri, form etkileşimleri — görünmez hale geliyor.
Yapay Zeka Trafiğinin Parmak İzleri
Ajanları sunucu loglarınızda nasıl tanıyacaksınız? İşte temel HTTP imzaları:
| Ajan | HTTP İstemcisi | Karakteristik İmza |
|---|---|---|
| Claude Code | Node.js / Axios | axios/1.8.4 |
| Cline | curl | curl/8.4.0 + OpenAPI taraması |
| Cursor | Node.js / got | HEAD probe → GET |
| Windsurf | Go / Colly | colly |
| Aider | Headless Chromium | Tam Mozilla/Safari user-agent |
| VS Code | Electron / Chromium | Chromium + Electron işaretçileri |
Bu imzaları bir kez tanımladığınızda, kendi loglarınızda ne kadar AI ajanı trafiği olduğunu görmek sizi şaşırtabilir.
Token Ekonomisi: Dökümanlarınız Ajanlara Görünmez Olabilir
AEO’nun en az takdir edilen boyutu budur: token ekonomisi.
Ajanların sonsuz bağlamı yok. Çoğu 100K-200K token arasında pratik sınırlarla çalışıyor ve bağlam yönetimi her görevde aktif bir kısıt. Şöyle somut bir örnek düşünün: Cisco’nun bir REST API hızlı başlangıç kılavuzu 193.217 token — yani 718.000 karakterden fazla. Tek bir döküman, birçok ajanın kullanılabilir bağlam penceresinin tamamını tüketiyor ya da aşıyor.
Bir ajan aşırı uzun bir belgeyle karşılaştığında şunlar olabilir — hiçbiri iyi değil:
- Kritik bilgileri sessizce kesiyor olabilir
- Dökümanı daha kısa bir şey lehine tamamen atlıyor olabilir
- Gecikme ve hata riski yaratacak şekilde parçalara bölmeye çalışıyor olabilir
- Parametrik bilgiye — yani mevcut eğitim verisine — geri düşüyor olabilir: başka bir deyişle, bir şeyler uyduruyor olabilir
Token sayısı artık birinci sınıf bir döküman metriğidir. Döküman sayfalarınızın token sayısını takip etmiyorsanız, ajanların içeriğinizi okumaya çalışıp çalışmayacağına karar vermek için kullandıkları bir sinyali kaçırıyorsunuz.
Pratik Token Hedefleri
- Hızlı başlangıç / başlarken sayfaları: 15.000 token altı
- Tekil API referans sayfaları: 25.000 token altı
- Tam API referansı: Ürün değil, kaynak/endpoint bazında parçalara bölün
- Kavramsal rehberler: 20.000 token altı; detayı gömmeyin, bağlantı verin
AEO Stack’i: Ne İnşa Etmeli?
AEO tek bir şey değil — katmanlı bir sinyal ve standartlar setidir.
Katman 1: Erişim Kontrolü — robots.txt
Bu, ajanın ilk durağı. İçerik çekmeden önce birçok ajan robots.txt‘i kontrol ederek nelere erişmesine izin verildiğini belirliyor.
Bilinen AI tarayıcı user-agent’larını engelleyen yanlış yapılandırılmış bir robots.txt, ajanları dökümanlarınıza sessizce erişimden mahrum bırakıyor. Trafik yok, hata yok, hiçbir şeyin yanlış gittiğine dair bir işaret yok.
Pratik adımlar:
robots.txt‘inizi AI agent user-agent’larına yönelik istem dışı engellemeler için denetleyin- Bilinen AI agent kalıplarını (Anthropic, OpenAI, Google, Perplexity tarayıcıları) açıkça izin verilen listesine almayı düşünün
- Daha ayrıntılı kontrole ihtiyaç duyuyorsanız
agent-permissions.json‘a bakın: hangi otomatik etkileşimlerin izin verileceğini, hız sınırlarını ve tercih edilen API endpoint’lerini bildirimsel olarak belirtmenizi sağlayan yeni bir standart
Katman 2: Keşfedilebilirlik — llms.txt
Bir ajan içeriğinize erişebilse bile doğru içeriği bulmaya ihtiyaç duyuyor. llms.txt burada devreye giriyor.
llms.txt‘i yapay zeka ajanları için bir site haritası olarak düşünün. yourdomain.com/llms.txt adresinde barındırılan, düz Markdown biçimli bu dosya, ajanların sitenizin tamamını taramak zorunda kalmadan neyin ilgili olduğunu anlayabilmesi için açıklamalar içeren yapılandırılmış bir döküman dizini sunuyor.
İyi bir llms.txt nasıl görünür:
# YourProduct Dokumentasyonu
## Başlarken
- [Hızlı Başlangıç Kılavuzu](/docs/quickstart): 5 dakikada kurulum ve ilk API çağrısı
- [Kimlik Doğrulama](/docs/auth): OAuth 2.0 ve API anahtarı kimlik doğrulama kalıpları
## API Referansı
- [REST API Genel Bakış](/docs/api): Temel URL'ler, sürüm oluşturma, sayfalama, hata kodları (~12K token)
- [Kullanıcılar API'si](/docs/api/users): Kullanıcı yönetimi için CRUD operasyonları (~8K token)Dikkat edilmesi gerekenler:
- Açıklamalar sayfanın ne olduğunu değil, ajana ne bulacağını söylemeli
- Mümkünse sayfa başına token sayısı ekleyin
- Ürün hiyerarşisine göre değil, göreve göre organize edin
- Kendisi de 5.000 token’ı geçmemeli
Katman 3: Kapasite Sinyali — skill.md
llms.txt ajanlara nerede şeyler olduğunu söylüyor. skill.md ise ürününüzün gerçekte ne yapabildiğini söylüyor.
Bu ayrım önemsendikçe daha önemli görünüyor. Bir ajanın nesir dökümanlardan kapasiteler çıkarmak zorunda kalması yerine, skill.md bunları bildirimsel olarak yüzeye çıkarıyor — niyetleri endpoint’lere ve kaynaklara eşliyor.
Bir kimlik doğrulama servisi için skill.md örneği:
---
name: auth-service
description: Kullanıcı kimlik doğrulama, OAuth 2.0 akışları ve oturum yönetimi
---
## Neler yapabilirim
- OAuth 2.0 ile kullanıcı kimliği doğrulama (authorization code, PKCE)
- JWT token'ları oluşturma ve doğrulama
- SSO sağlayıcılarıyla entegrasyon (SAML, OIDC)
## Gerekli girdiler
- İstemci ID ve İstemci Secret
- Yönlendirme URI (önceden kayıtlı olmalı)
## Kısıtlamalar
- Hız sınırı: uygulama başına dakikada 1000 token isteği
- Token süresi: erişim token'ları 1 saat, yenileme token'ları 30 günKatman 4: Ajan Dostu İçerik Biçimlendirmesi
Mükemmel keşfedilebilirlik ve kapasite sinyali olsa bile içeriğin ajan tarafından okunabilir olması gerekiyor.
Markdown sunun, yalnızca HTML değil. Birçok döküman platformu URL’ye .md ekleyerek ham Markdown’a erişmenizi sağlıyor. Bunu keşfedilebilir kılın. Ajanlar Markdown’ı HTML’e kıyasla çok daha düşük token ek yükü ile işliyor.
Okumak için değil, taramak için yapılandırın:
- Tutarlı başlık hiyerarşileri kullanın (H1 → H2 → H3, atlama yok)
- Her bölüme arka planla değil, çıktıyla başlayın
- Kod örneklerini hemen açıkladıkları iddiadan sonra koyun
- Parametre referansları için tablo kullanın — nesir listelerinden daha az yer kaplıyorlar
Navigasyon gürültüsünü ortadan kaldırın. HTML’inizde görünen yan çubuklar, ekmek kırıntıları ve altbilgi bağlantıları, Markdown/metin için sadece gürültü.
En kullanışlı şeyleri öne alın. Her sayfanın ilk 500 token’ı şunu yanıtlamalı: bu nedir, ne yapabilir ve başlamak için ne gerekiyor?
Katman 5: Token Yüzeyleme
Döküman sayfalarınızda token sayılarını görünür kılın — hem llms.txt dizininde hem de sayfaların kendisinde (meta etiket ya da sayfa başlığı olarak).
Bu, ajanlara akıllı kararlar almak için ihtiyaç duydukları bilgiyi veriyor:
- “Bu sayfa 8K token — tamamını bağlama dahil edebilirim”
- “Bu sayfa 150K token — sadece ilgili bölümü çekeceğim”
Uygulama basit: karakter sayısını sunucu tarafında sayın, yaklaşık token tahmini için 4’e bölün ve meta etiket veya HTTP yanıt başlığı olarak ifade edin.
Katman 6: “Yapay Zeka için Kopyala” Butonu
Bir IDE’de çalışan ve dökümanı bağlam olarak dahil etmek isteyen geliştirici şu an render edilmiş HTML’den kopyalayıp yapıştırıyor — navigasyon, altbilgi, her şey dahil. Temiz Markdown’ı panoya kopyalayan bir “Yapay Zeka için Kopyala” butonu küçük bir şey ama ajanın aldığı bağlamın kalitesini anlamlı biçimde artırıyor.
Anthropic, Cloudflare ve diğerleri bu özelliğin varyantlarını halihazırda sunuyor.

AGENTS.md: Yeni Varsayılan Giriş Noktası
README.md insan geliştiriciler için varsayılan giriş noktası haline geldiği gibi, AGENTS.md de yapay zeka ajanları için aynı rolü üstleniyor. Bir kodlama ajanı projeyi açtığında kök dizindeki AGENTS.md‘yi arıyor ve talimatlarını her sonraki göreve taşıyor.
İyi bir AGENTS.md şunları içeriyor:
- Proje yapısı ve temel dosya konumları
- İlgili API veya servis dökümanlarına doğrudan bağlantılar
- Kullanılabilir geliştirme sandbox’ları ve test ortamları
- Ajanın bilmesi gereken hız sınırları ve kısıtlamalar
- Tercih edilen kalıplar ve kod tabanı kuralları
- Varsa MCP server bağlantıları
Yapay Zeka Yönlendirme Trafiğini İzlemek
Şu an yapabileceğiniz bir şey: analitik verilerinizde AI yönlendirme trafiğini takip etmeye başlayın.
İzlemeye değer yönlendirme kaynakları:
claude.ai/referral
chatgpt.com/(none)
perplexity.ai/referral
copilot.microsoft.com/referral
gemini.google.com/referralAyrıca referans olmadan gelen doğrudan ajan trafiğini yakalamak için HTTP parmak izlerini de izlemeniz gerekiyor: axios/1.8.4, curl/8.4.0, got (sindresorhus/got), colly.
Uygun bir AI trafik segmenti oluşturmak, bu çalışmanın gerçekten fark yaratıp yaratmadığını gösteren öncü göstergelerinizi verecek.
Developer Experience’ın Geleceği
AEO, teknik bir kontrol listesinden daha büyük bir şeye işaret ediyor.
Web tarihinin büyük bölümünde geliştirici portalları insan bilişsel kalıpları etrafında tasarlandı: aşamalı açıklama, görsel hiyerarşi, interaktif örnekler, rehberli eğitimler. Bunların hepsi her adımda bir insanın döngüde olduğunu varsayıyor.
Ajan ağırlıklı bir dünyada bu varsayımların büyük bölümü çöküyor:
- Görsel hiyerarşi alakasız — ajanlar düzenleri değil, metni okuyor
- Aşamalı açıklama bir engele dönüşüyor — ajanlar her şeyi bir anda istiyor
- Kullanıcı yolculukları çöküyor — çok bölümlü bir eğitim tek bir bağlam yüküne dönüşüyor
Bu, insan merkezli tasarımın önemini yitirdiği anlamına gelmiyor. İnsanlar hâlâ döküman okuyor. Ama giderek daha fazla bir yapay zeka asistanının bağlamı içinde okuyor — yani ajan çoğunlukla birincil tüketici, insan ise nihai yararlanıcı oluyor.
İleride en iyi dökümanlar muhtemelen her iki kitleye aynı anda hizmet edecek: insanlar için taranabilir ve iyi yapılandırılmış, ajanlar için makine tarafından okunabilir ve token açısından verimli.
AEO Denetim Kontrol Listesi
Keşfedilebilirlik
-
llms.txttüm dökümanların yapılandırılmış diziniyle kök dizinde mevcut -
robots.txtbilinen AI ajan user-agent’larını istem dışı engellemiyor -
agent-permissions.jsonotomatik istemciler için erişim kurallarını tanımlıyor - Kod depolarında ilgili dökümanlarla
AGENTS.mdmevcut
İçerik Yapısı
- Döküman sayfaları temiz Markdown olarak erişilebilir
- Her sayfa ilk 200 kelimede net bir çıktı ifadesiyle başlıyor
- Başlıklar tutarlı ve hiyerarşik olarak doğru
- Kod örnekleri nesir açıklamalarından hemen sonra geliyor
- Parametre referansları iç içe nesir yerine tablo kullanıyor
Token Ekonomisi
- Döküman sayfası başına token sayıları takip ediliyor
- Chunking stratejisi olmaksızın hiçbir tek sayfa 30.000 token’ı geçmiyor
- Önemli sayfalar için
llms.txt‘te token sayıları gösteriliyor - Token sayıları sayfa meta verisi olarak erişilebilir
Kapasite Sinyali
-
skill.mddosyaları her servisin/API’nin sadece nasıl çağrılacağını değil, ne yaptığını açıklıyor - Her skill şunları içeriyor: kapasiteler, gerekli girdiler, kısıtlamalar, temel döküman bağlantıları
- Varsa ajanlarla doğrudan entegrasyon için MCP server mevcut
Analitik
- Web analitiğinde AI yönlendirme kaynakları segmentlenmiş durumda
- Sunucu logları bilinen AI ajan HTTP parmak izleri için izleniyor
- AI ile insan trafik oranı için temel ölçüt oluşturulmuş
UX Köprüsü
- Döküman sayfalarında “Yapay Zeka için Kopyala” butonu mevcut
- Markdown kaynağı URL kuralıyla erişilebilir (örn.
.mdeklenmesi)
Nereden Başlamalı?
Listeye bakıp nereden başlayacağınızı soruyorsanız, şu sırayı öneririm:
robots.txt‘inizi denetleyin — on dakika iş, sessiz ajan engellemesini önlerllms.txtekleyin — birkaç saat, anlık keşfedilebilirlik kazanımları- Token sayılarını ölçün ve yüzeyleyin — yüksek kaldıraçlı bir hafta sonu projesi
- En yoğun kullanılan 3 API’niz için
skill.mdyazın — ajanların en çok ulaştığı şeylerle başlayın - “Yapay Zeka için Kopyala” butonları ekleyin — düşük çaba, yüksek sinyal
- AI trafik izleme kurun — her şeyi haklı kılacak veriyi size verir
Sonuç
SEO bize şunu öğretti: harika içerik yeterli değil — onu dönemin gerçek trafik kalıplarına uygun şekilde keşfedilebilir kılmanız gerekiyor. AEO aynı ders, sadece farklı bir tüketici için.
AI kodlama ajanları zaten döküman trafiğinin önemli ve büyüyen bir payını oluşturuyor. İnsan okuyuculardan temel olarak farklı davranıyorlar. Ve çoğu geliştirici portalı henüz onlar için inşa edilmemiş.
Burada erken hareket eden ekipler gerçek bir avantaja sahip olacak: API’leri, ajanların önerdiği, başarıyla entegre ettiği ve geri döndüğü API’ler olacak. Olmayanlar ise döküman kalitesi ile gerçek ajan görevi başarısı arasında büyüyen boşluklar görecek — ayıklaması gerçekten zor, sessiz bir başarısızlık modu.
İyi haber şu ki ajanlar için inşa etmek, dökümanları insanlar için de daha iyi yapma eğiliminde. Disiplinler birbirinden ayrışmaktan çok örtüşüyor.
llms.txt ile başlayın. Bir skill.md gönderin. robots.txt‘inizi denetleyin. Token’larınızı ölçün.
Bu yazı Addy Osmani’nin “Agentic Engine Optimization (AEO)” başlıklı makalesi baz alınarak hazırlanmıştır.
İlgili Okumalar: